Hough Transform-based Mouth Localization for Audio-Visual Speech Recognition
Gabriele Fanelli, Juergen Gall, and Luc Van Gool
Abstract
We present a novel method for mouth localization in the context of multimodal speech recognition where audio and visual cues are fused to improve the speech recognition accuracy. While facial feature points like mouth corners or lip contours are commonly used to estimate at least scale, position, and orientation of the mouth, we propose a Hough transform-based method. Instead of relying on a predefined sparse subset of mouth features, it casts probabilistic votes for the mouth center from several patches in the neighborhood and accumulates the votes in a Hough image. This makes the localization more robust as it does not rely on the detection of a single feature. In addition, we exploit the different shape properties of eyes and mouth in order to localize the mouth more efficiently. Using the rotation invariant representation of the iris, scale and orientation can be efficiently inferred from the localized eye positions. The superior accuracy of our method and quantitative improvements for audio-visual speech recognition over monomodal approaches are demonstrated on two datasets.
Images/Videos
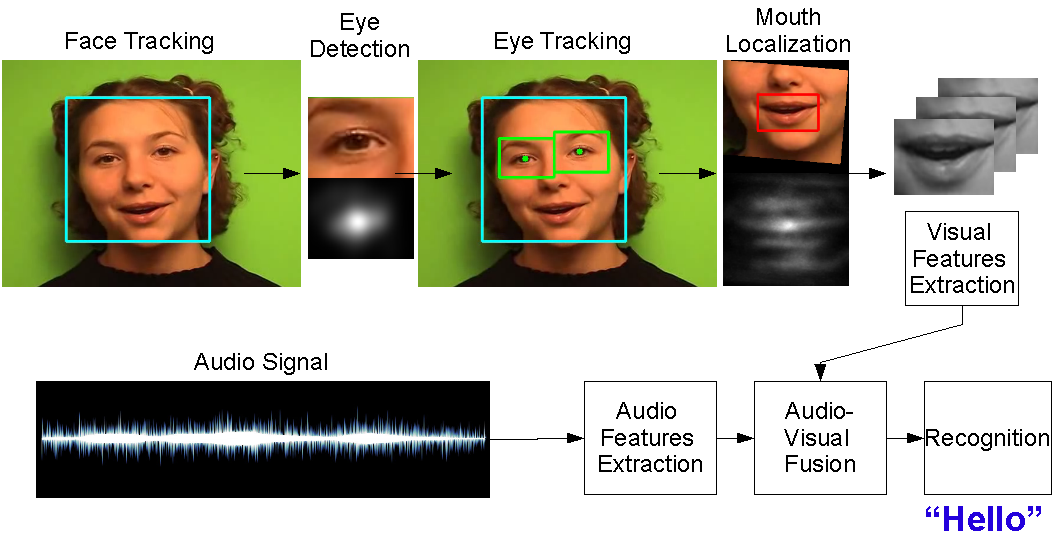 |
Publications
Fanelli G., Gall J., van Gool L., Hough Transform-based Mouth Localization for Audio-Visual Speech Recognition (PDF), British Machine Vision Conference (BMVC'09), 2009.
Gall J., Yao A., Razavi N., van Gool L., and Lempitsky V., Hough Forests for Object Detection, Tracking, and Action Recognition (PDF), IEEE Transactions on Pattern Analysis and Machine Intelligence, To appear.
Gall J. and Lempitsky V., Class-Specific Hough Forests for Object Detection (PDF), IEEE Conference on Computer Vision and Pattern Recognition (CVPR'09), 2009. ©IEEE