A Hough Transform-Based Voting Framework for Action Recognition
Angela Yao, Juergen Gall, and Luc Van Gool
Abstract
We present a method to classify and localize human actions in video using a Hough transform voting framework. Random trees are trained to learn a mapping between densely-sampled feature patches and their corresponding votes in a spatio-temporal-action Hough space. The leaves of the trees form a discriminative multi-class codebook that share features between the action classes and vote for action centers in a probabilistic manner. Using low-level features such as gradients and optical flow, we demonstrate that Hough-voting can achieve state-of-the-art performance on several datasets covering a wide range of action-recognition scenarios.
Images/Videos
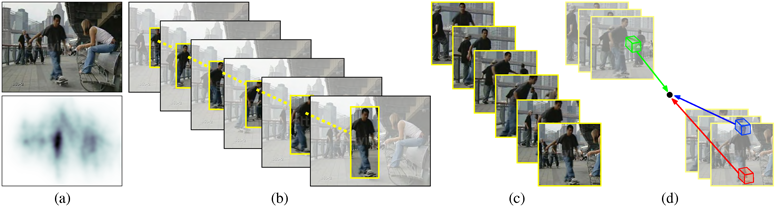 |
(a) Detection hypotheses are generated for each frame independently. (b) Particle filtering is used to link hypotheses across frames. (c) Action tracks. (d) Hough voting by 3D patches for action label and center. |
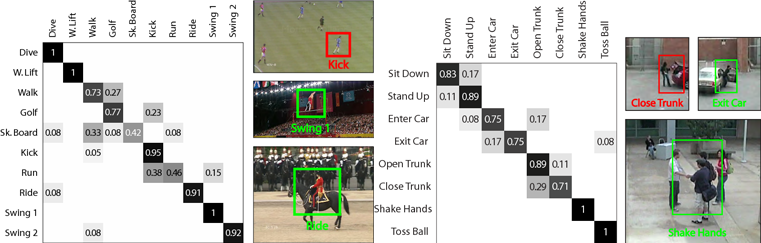 |
Source Code/Data
Bounding Box Annotations for Datasets
If you have questions concerning the annotations or source code, please contact Angela Yao.
Publications
Gall J., Yao A., Razavi N., van Gool L., and Lempitsky V., Hough Forests for Object Detection, Tracking, and Action Recognition (PDF), IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 33, No. 11, 2188-2202, 2011. ©IEEE
Waltisberg D., Yao A., Gall J., and van Gool L., Variations of a Hough-Voting Action Recognition System (PDF), Proceedings of the ICPR 2010 Contests, Springer, LNCS 6388, 306-312, 2010. ©Springer
Yao A., Gall J., and van Gool L., A Hough Transform-Based Voting Framework for Action Recognition (PDF), IEEE Conference on Computer Vision and Pattern Recognition (CVPR'10), 2010. ©IEEE
Gall J. and Lempitsky V., Class-Specific Hough Forests for Object Detection (PDF), IEEE Conference on Computer Vision and Pattern Recognition (CVPR'09), 2009. ©IEEE