Metric Learning from Poses for Temporal Clustering of Human Motion
Adolfo López-Méndez, Juergen Gall, Josep R. Casas, and Luc van Gool
Abstract
Temporal clustering of human motion into semantically meaningful behaviors is a challenging task. While unsupervised methods do well to some extent, the obtained clusters often lack a semantic interpretation. In this paper, we propose to learn what makes a sequence of human poses different from others such that it should be annotated as an action. To this end, we formulate the problem as weakly supervised temporal clustering for an unknown number of clusters. Weak supervision is attained by learning a metric from the implicit semantic distances derived from already annotated databases. Such a metric contains some low-level semantic information that can be used to effectively segment a human motion sequence into distinct actions or behaviors. The main advantage of our approach is that metrics can be successfully used across datasets, making our method a compelling alternative to unsupervised methods. Experiments on publicly available mocap datasets show the effectiveness of our approach.
Images/Videos
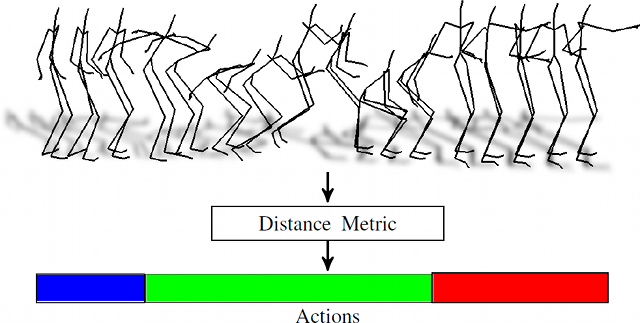 |
Human motion sequences are clustered into different actions using a learned distance metric. We use annotations available in mocap datasets to learn a distance metric that captures the semantic similarity between skeleton motion. |
Videos: Overview, Seq02, Seq04, Seq05, Seq06, Seq09, Seq11, Seq12, Seq14 |
Publications
López-Méndez A., Gall J., Casas J., and van Gool L., Metric Learning from Poses for Temporal Clustering of Human Motion (PDF), British Machine Vision Conference (BMVC'12), 2012.